Hybrid SQL Search
Combine vector similarity, full-text, and relational filters in a single SQL engine. Run hybrid search across your data—no extra pipelines or systems needed.

Find what matters with hybrid search
Scale to billions of embeddings and maintain control with SQL filters, joins, and ranking in a single runtime.

Relevant results,
every time
Retrieve answers that reflect context (semantic meaning) and precision (exact match).
Learn more

Search at any scale
Index and search billions of embeddings with low-latency, across cloud object storage or operational databases. Performance remains consistent as datasets grow.
Learn more

Build for scale with tools developers trust
A familiar, SQL-powered experience enables advanced search without leaving existing SQL workflows. Spice provides full transparency, control, and scalability with modern infrastructure behind the scenes.
Compose hybrid search in SQL
Write, filter, join, and re-rank using standard SQL commands like vector_search and text_search. Integrate advanced search directly into your analytics or application stack.
Learn more


Serve billions of records from cloud storage
Store, index, and retrieve embeddings with partitioned S3 vector indexing. Spice automatically manages ingest, refresh, and metadata for scalable, efficient queries.
Learn more
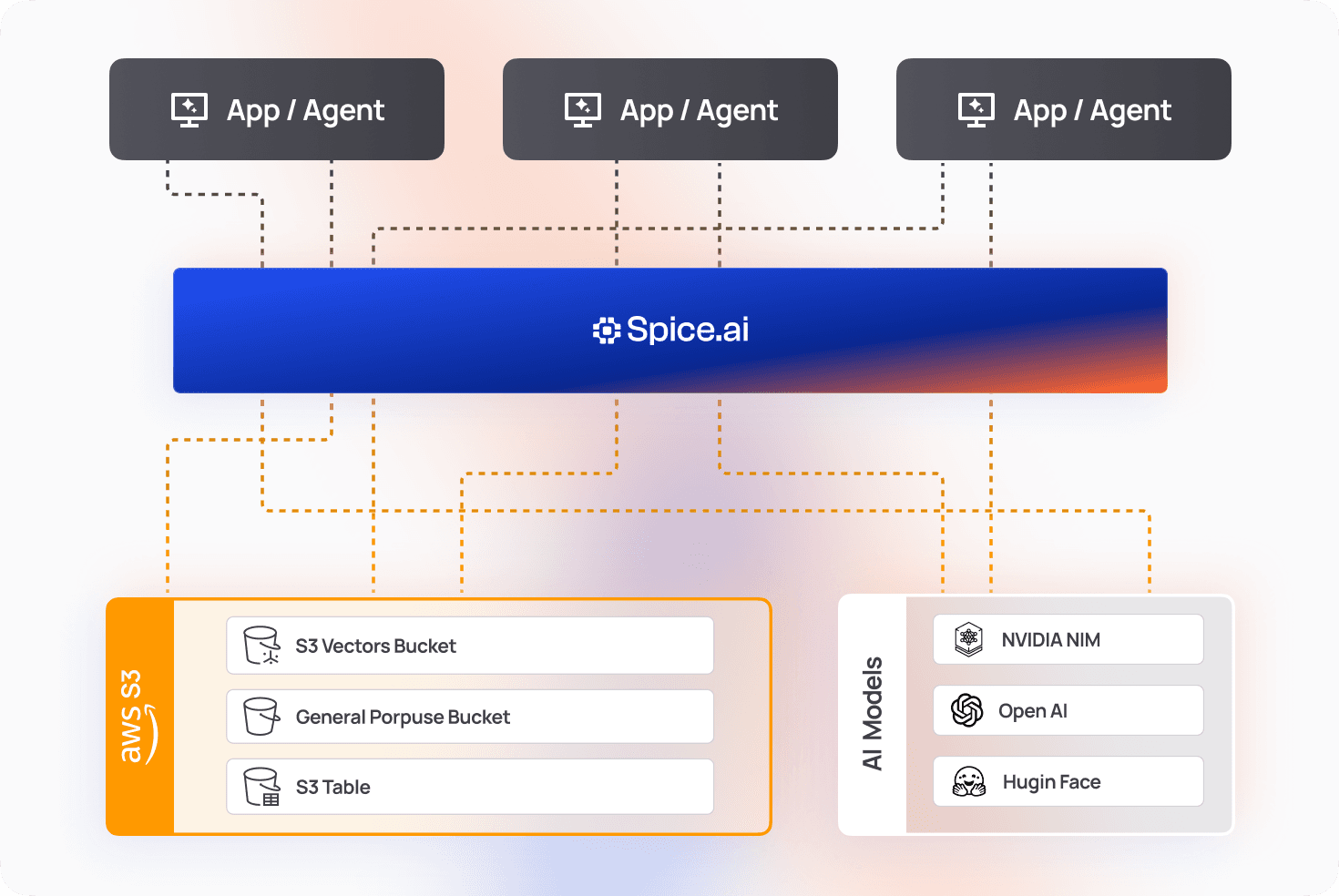
Fine-tune results with built-in controls
Spice hybrid search is fully expressed in standard SQL, letting you filter, join, re-rank with reciprocal rank fusion, and project fields within each query with zero middleware.
Learn more
Trusted in production
Teams use Spice to replace complex search stacks with one engine that’s fast, scalable, and controllable—without standing up additional systems.




“Spice AI grounds AI in our actual data, using SQL queries across all our data. This brings accuracy to probabilistic AI systems, which are very prone to hallucinations.”
Rachel Wong
CTO, Basis Set

"Partnering with Spice AI has transformed how NRC Health delivers AI-driven insights. By unifying siloed data across systems, we accelerated AI feature development, reducing time-to-market from months to weeks - and sometimes days. With predictable costs and faster innovation, Spice isn't just solving some of our data and AI challenges - it’s helping us redefine personalized healthcare.”
Tim Ottersburg
VP of Technology, NRC Health
Integrations across all of your data sources
Accelerate your data stack with a library of 30+ prebuilt connectors for the most common databases, warehouses, and file stores—from Databricks and S3 to MySQL and PostgreSQL.

FAQs
How does hybrid search work?
Hybrid search in Spice.ai merges vector similarity (semantic) and full-text BM25 (keyword) results into one ranked output. Both search types run in parallel, and their ranks are combined using Reciprocal Rank Fusion (RRF) for optimal relevance.
You can query this through the /v1/search API or with SQL functions like vector_search() and text_search(). Because results are treated as tables, you can filter, join, and aggregate just like any SQL dataset.
How is Spice.ai different from a vector database?
Traditional vector databases require you to pair a vector index with separate text and keyword search systems, all running on clusters you have to provision and maintain. Spice.ai unifies vector, text, and relational search in a single runtime that you can deploy locally, in your cloud, or fully managed.
You can join vector results with structured data, apply SQL filters, and run inference on top of them, all without moving data or managing multiple systems. For developers, this means a single query layer that delivers the power of a vector database, the flexibility of SQL, and the speed of an accelerated cache.
When should I use S3 Vectors?
Use S3 Vectors when you need to store and query embeddings at large scale. It’s ideal for workloads with millions or billions of vectors that don’t need always-on compute. By offloading storage and similarity search to S3 Vectors, you get the scalability and durability of S3 with sub-second queries via transient compute. Spice manages the entire lifecycle: embedding, indexing, filtering, and query orchestration.
See Spice in action
Get a guided walkthrough of how development teams use Spice to query, accelerate, and integrate AI for mission-critical workloads.
Get a demo


